FUTURE CASTという近未来の出来事を予想して遊べるサイトを公開しました!
こんにちは! 今回は先日リリースした、「FUTURE CAST」サイトに関してご紹介させていただきます。
サイトのご紹介
FUTURE CASTは近未来の出来事をゲーム感覚で予想しながら遊べるサイトです。
トップページ

トップページには近未来の出来事に関する 問題 がリストされており、たとえば「2021年のM-1グランプリで錦鯉が優勝する?」のような問題が投稿されています! 問題 はGoogleアカウントなどでログインして誰でも投稿することができます。 一覧の中から、気に入った問題を選択すると詳細が表示されます。
問題の詳細ページ
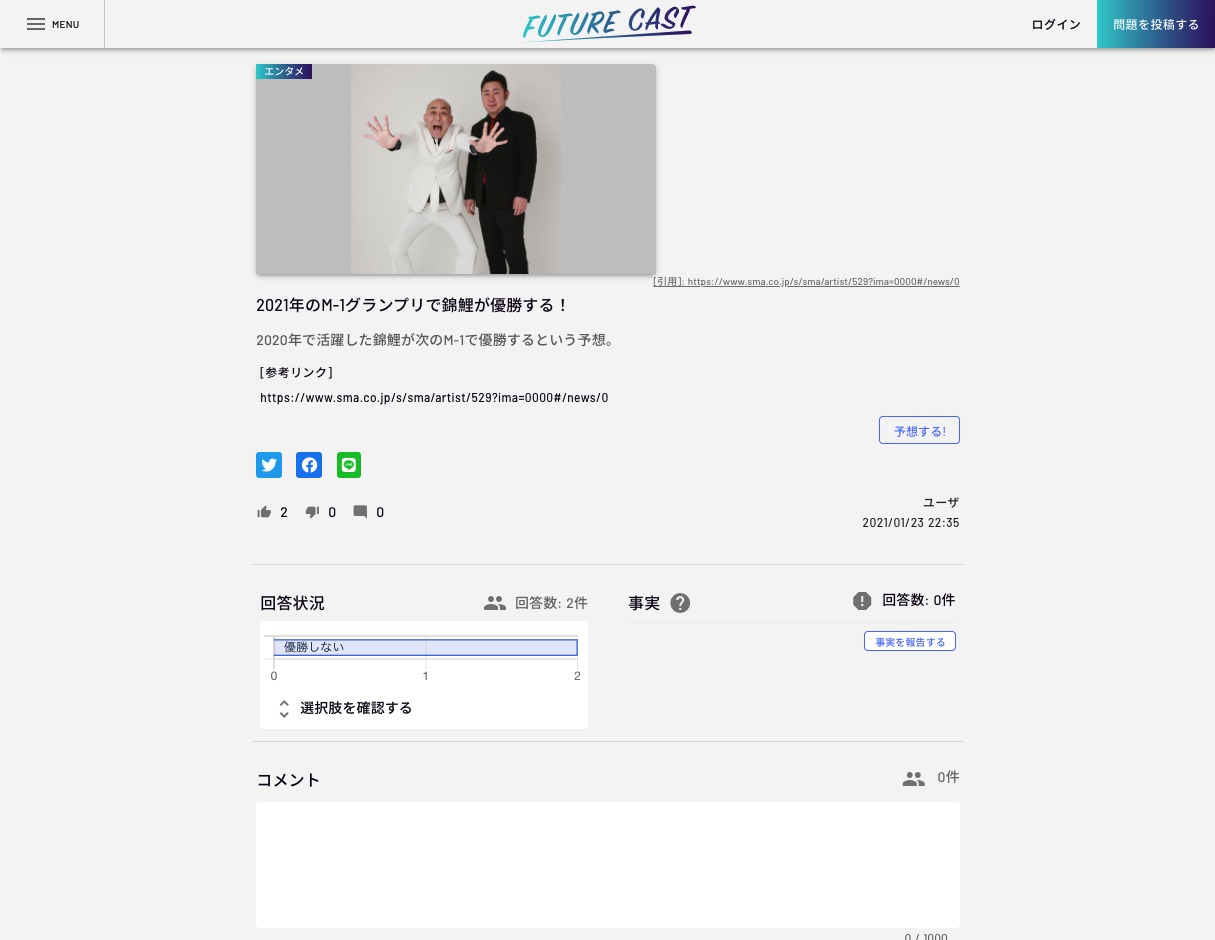
このページから、問題の予想を行ったり、みんなの予想の統計をみたり、問題の結果を報告したりすることができます。 また、コメント欄もあるので、この話題に関してユーザ同士で意見公開ができるようになっています!
問題の答えが判明すると各ユーザに自動的に特典が割り振られるようになっており、 定期的にランキングページに反映されます。
ランキングページ
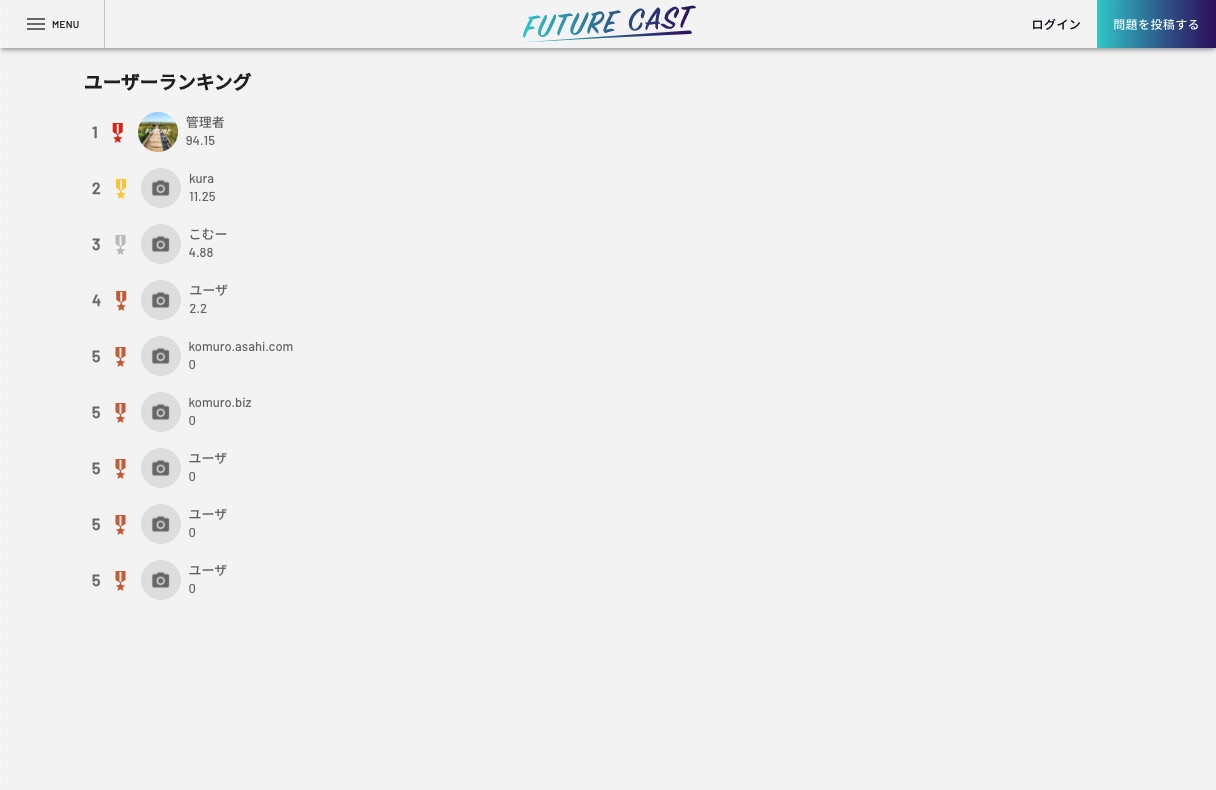
詳細な使い方はこちらにまとめております。
ユーザが主役となってみなさんで盛り上げていけるサイトなので、是非是非一度遊んでみてください。
開発の話
テックブログなので、ここからは開発に関するお話をしたいと思います!
技術選定
ざっくりこんな感じです。
フロントエンド => Nuxt.js
インフラ => firebase
Nuxtは単純に使い慣れているのと、FirebaseはDB + Authenticationが非常に魅力的なので選定しました。
データベース
FirebaseのFireStoreは個人開発をすると気に非常に便利です。ざっくり言ってもこんな感じで利点があります。
- リアルタイム
- 料金が安いし
- SDKなど使い安い
- クエリの条件が割と柔軟
- ドキュメント間のリレーションを定義できる
特に料金は衝撃的です。1Mの読み込みに対してたったの0.36$です。スモールスタートしたいサイトの運営にはもってこいですね。
データの分割
さて、FireStoreを使うとなると悩ましいのがデータ設計ですね。 Firestoreに関して少し調べてみましたが、何がベストプラクティスなのかつかみどころがないなぁという印象でした。 例えば、サブコレクションいつ使う?問題があったり、ドキュメントをどこまで分割するか問題など悩みました。
結論として、今回はデータ間の依存関係は全て参照で表現することにしました。
参照を使用する方法は単体のドキュメントを小さく保つことができますが、 参照を解決するには複数のドキュメントを読み込んでクライアントサイドでジョインする必要があります。 Firebaseの課金方式はドキュメントのサイズには依存せず、ドキュメントの読み込み個数なので、料金的にはデメリットがあります。
しかしながら、非正規化されたデータは整合性を保ったまま更新することに最新の注意を払う必要があります。 例えば、質問(Question)の作成者(User)はUserコレクションと、Questionのドキュメント内に重複して存在します。 この場合はUserを更新する時にQuestionを同時に編集する必要があります。
この様な管理コストの観点から、今回は参照を利用することに決めました。ちなみに参照だけでも、配列の長さなどは取れます。 例えば、質問の回答者一覧をUserのrefの配列にしておくと、「回答数」という統計情報は取得することができます。 一方、以下の様なデータは全てのドキュメントをフルスキャンしてしないと基本的に取得することはできません。
- ユーザのランキング
- 回答のサマリー ( 「A」と回答した人がx人, 「B」と回答したひとがy人, ... )
ランキングは仕方がないので、定期的にUserコレクションをフルスキャンして、Rankingコレクションにドキュメントを追加していく方式にしました。 一方、回答のサマリーはリアルタイムに反映させたいので、誰かが回答する度にAnswerSummaryコレクションに回答を追記していく方法にしました。
export class AnswerSummary<SelectionDocumentReference> implements TableBase {
values: {
// ここに追記
[userId: string]: SelectionDocumentReference | string | number;
};
isActive: boolean;
createdAt: string;
constructor( summary: AnswerSummary<SelectionDocumentReference> ) {
Object.assign( this, summary );
}
}
アクセス制御
アクセス制御はルールで記述することができます。ルールはJavaScriptっぽい感じでかけて、VSCodeであればハイライトツールもあったので、割と描きやすい感じです。
例
/* 独自関数も定義できる */
// アクティブなリソースのみ
function isActive() {
return resource != null && resource.data.isActive == true;
}
// クエリのリミット
function queryLimit( limit ) {
return request.query != null && request.query.limit <= limit;
}
// User
match /users/{userId} {
// 単体取得: ログイン済みのみ
allow get: if isActive();
// 複数取得: 20個まで
allow list: if isActive() && queryLimit( 20 );
// 新規追加: ログイン済みのみ
allow create: if isAuth();
// 更新: 自身のユーザ情報のみ
allow update: if isAuth() && request.auth.uid == resource.id;
}
ルールはフィルターとして機能するものではなく、クエリ条件を許可するものなので、
結果的にルールを満たすとしても、明示的に条件を指定しないとBanされます。
例えば、クエリのリミットが20である場合、現在のデータベースに10個しかデータがなくても
.limit(20)をしっかり指定してあげないとエラーします。
また、フィールド単位のアクセス制御はルールで対応できません。 たとえば、「Questionコレクションのコメント一覧へのコメントの追加はログインユーザ全員ができる」、という条件は定義できません。 その場合は Firebase Functionを使用して、自身のコードで認可してあげるといった対策ができます。
Nuxt.jsへのつなぎこみ
前提として、サーバサイドとクライアントサイドで使用するnpmモジュールは異なり、それぞれfirebase-admin、firebaseとなります。そのため、SSR時をする際は注意が必要です。
また、firebaseを使用して取得したデータはそのままではVuexに格納することができません。Firebaseはリアルタイムなためイベントを制御するためのメタデータが取得データに含まれているのですが、
これをfirebaseが変更するので、VuexのStateに格納すると不正なミューテーションが検知されアプリケーションがクラッシュします。
対策としては、vuexfireを利用します。
このライブラリはリアルタイムならではの複雑な考慮点を隠蔽しながら、取得データをimmutableな形にserializeしてからVuexに格納してくれます。
無限スクロール
リアルタイム機能を使用する場合に難しいのは無限スクロールです。 スクロールにしたがって追加コンテンツを読み込みますが、リアルタイムに追加されるデータも反映していくにはどうすれば良いでしょうか?
これに関して、クエリカーソル が活用できます。 カーソルはデータの取得開始位置をドキュメントのメタデータで指定することができます。
公式サイトより
return first.get().then(function (documentSnapshots) {
var lastVisible = documentSnapshots.docs[documentSnapshots.docs.length-1];
var next = db.collection("cities")
.orderBy("population")
// ここ!
// 「このドキュメントの後」みたいな指定ができる
.startAfter(lastVisible)
.limit(25);
});
これを用いて以下の様に実装しました。(limitを10として)
- DB上で一番最初のデータ(X)を取得する
- Xを1ページ目の最後の要素のカーソルにする(.endAt( X )として、1ページ目はXとそれより新しいアイテムが格納される)
- Xの次から10個アイテムを取得して、最後のアイテムをYとする時、2ページ目はXよりあとで、Y前のアイテムが入る様にする 以下くりかえし。
う〜ん、各ページごとに2回ずつデータを取得しないと行けないし、実際上記のロジックを組んでみるとかなり複雑だし、 これにさらにSSRが加わったら?と思うとゾッとしますが、今回は全てやってしまいました。 あまりお勧めではないです。 ここは無限スクロールの要件からリアルタイムを落とすのが正解だと思います。
Firebase Authentication
ムッチャ便利です。firebaseSDKから簡単にログイン操作ができますし、SNS連携ログインも簡単にセットアップできます。 セルフサインアップは無効化できないので、toC向けサイトにしか使えないですね。
ログインページはfirebase-uiで作成可能です。デフォルトでは英語表記になっていますが、各言語のパッケージを自分でビルドすることで、 日本語Versionを生成することもできる様になっています。
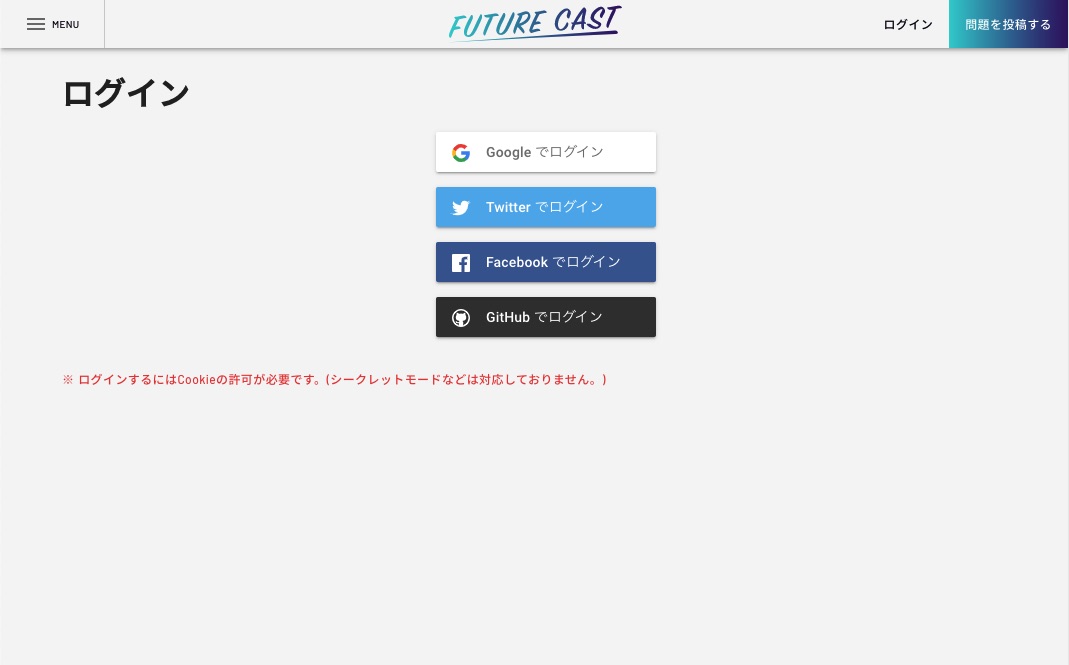
こういったエンベッド系のツールはSPAフレームワークと相性が悪いですが、そこは無理やりと埋め込みます!
Firebase Function
Firestoreの部分で言った様な、複雑なDBの更新作業や、細かいアクセス制御を行う時に活用します。
ムッチャ便利ですが、最初使う時はディレクトリ構成が少し癖がありました。 ルートディレクトリのfirebase.jsonがこうなっている場合、
"functions": {
"source": "firebase/functions"
},
firebase deployを実行した時にデプロイの挙動は、firebase/functions/package.jsonに従います。
このpackage.jsonの通りライブラリをインポートし、mainで指定されたjsをエントリーポイントとします。
あともう一癖、firebaseFunctionsはプロジェクトの全ての関数において共有のコードを共有する様な形になっています。
関数が増えるにしたがって、コールドスタートのパフォーマンスに影響を与えそうですが、仕方がないようです。
(モジュールの読み込みだけlazy化させる方法がある様ですが、、)
関数の記述について、function.https.onCallとfunction.https.onCallの二つがありますが、基本的にonCallの方を使用します。
onCallの場合、firebase SDKでクライアントを生成し、コールする形になります。自動的にFirebase Authenticationで発行された認証トークン(jwt)を検証し、
ユーザの情報を関数内に提供してくれるため、「ログイン済みにのみ許可」などの条件分岐が簡単に記述できます。
そのほか、クーロン式に起動する時限関数や、Firestoreで特定のデータが更新された時にトリガーされるトラップカードの様な関数も作成できます。
フロント
フロントは当初SPAページとして作成し、Firebase Hostingで公開をしました。 しかしながら、実際にSPAで公開してみるとトップの問題一覧の読み込みをGoogleのクローラが待ってくれないことが発覚し、 例えばAdsenseなどの審査にこのままでは通らないということが判明しました。
そこで、本当に色々と紆余曲折の末、AWS LambdaからSSRでホストするといった少しトリッキーな方法に落ち着きました。 紆余曲折の内容も長くなりますが、こちらの記事にまとめました。
まとめ
今回は初めてfirebaseをがっつりと使ってWEBサービスを作ってみました。 Firebaseを組み込んだ開発は今まで経験してきた開発とちょっと一癖違った世界があったりするので、 また違う経験値が要求されるなぁと感じました。ただ、一度なれてしまうともう戻れないくらい便利で安いサービスですので、 今後も機会があれば活用させて頂きたいなぁと思いました。
という訳で FUTURE CAST サイトをよろしくお願いいたします。
※ 取り組みに興味を持っていただける方がいましたら、twitterまでご連絡頂けると幸いです。